“Nunca produzimos tanto código quanto hoje. Mas nunca fomos tão exaustos.”
Salve galera! Esse artigo é diferente dos que costumo escrever. Não é um tutorial, não é um guia prático. É uma reflexão, fundamentada em dados, pesquisas e experiência pessoal, sobre algo que eu venho sentindo no dia a dia e que acredito que muitos de vocês também sentem: a sensação de que, apesar de todas as ferramentas de IA nos tornando “mais produtivos”, o trabalho de desenvolver software ficou mais cansativo mentalmente.
Nos últimos dois anos, assistimos a uma revolução na forma como escrevemos código. GitHub Copilot, Cursor, Claude, agentes autônomos, vibe coding… A promessa é tentadora: produzir mais, mais rápido, com menos esforço. Mas será que essa promessa está se cumprindo? Ou estamos trocando um tipo de esforço por outro, um que é mais difícil de medir e mais perigoso de ignorar?
Vamos explorar isso juntos.
1. O Paradoxo da Produtividade com IA
Vamos começar pelos números. Porque os números são bons, certo?

Em 2024, o GitHub publicou um estudo em parceria com a Accenture envolvendo milhares de desenvolvedores em um ensaio controlado randomizado (RCT). Os resultados foram impressionantes:
- 55% mais rápido na escrita de código com Copilot
- 90% dos desenvolvedores se sentiram mais satisfeitos com o trabalho
- 95% disseram que gostam mais de codar com Copilot
- 70% reportaram menos esforço mental em tarefas repetitivas
- 84% de aumento em builds bem-sucedidos
- 15% de aumento na taxa de merge de pull requests
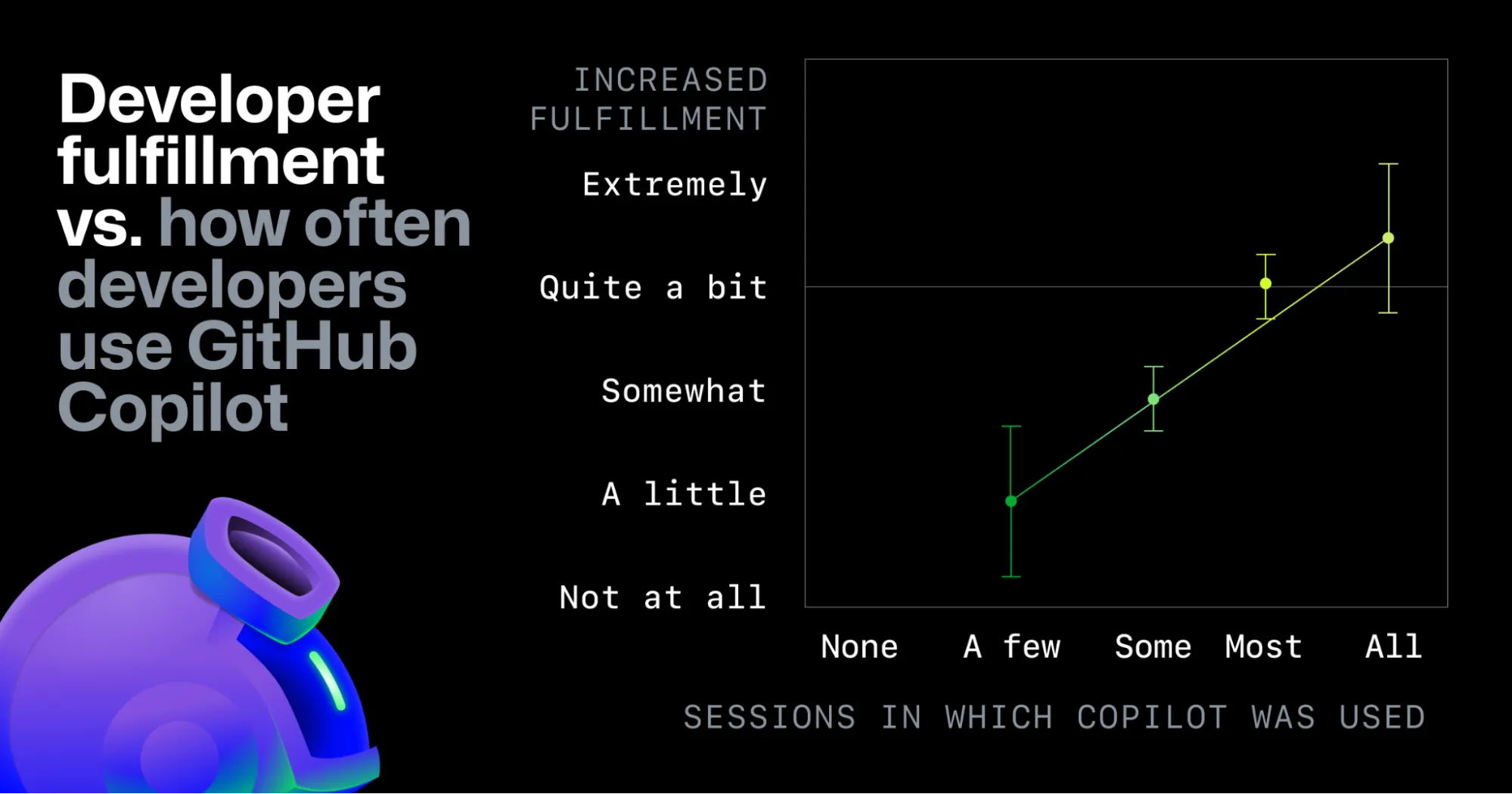
Esses números são reais. São significativos. E eu não os contesto… Ah! As referências estão todas no final do artigo 😉
O que eu contesto é o que eles não medem.
No mesmo período, a GitClear, uma empresa especializada em análise de qualidade de código, publicou uma pesquisa analisando mais de 153 milhões de linhas de código alteradas entre 2020 e 2023. O que encontraram pintou um quadro bem diferente:
- Code churn (linhas revertidas ou alteradas em menos de 2 semanas) projetado para dobrar em 2024 comparado com a baseline pré-IA de 2021
- Aumento desproporcional de código adicionado e copiado em relação a código refatorado, movido ou deletado
- O código gerado durante 2023 se parecia mais com o trabalho de um contractor temporário do que com o de um desenvolvedor sênior
Percebem o padrão? Por um lado, estamos escrevendo mais código, mais rápido, com mais satisfação subjetiva. Por outro, a qualidade e a manutenibilidade desse código estão sob pressão.
Estamos medindo linhas de código ou valor entregue?
Isso me lembra a Goodhart’s Law: “Quando uma métrica se torna meta, ela deixa de ser uma boa métrica.” Se medimos produtividade por PRs abertos, velocidade de digitação ou linhas geradas por hora, estamos otimizando para o indicador errado. E não é a primeira vez que a indústria comete esse erro: por décadas, a produtividade do desenvolvedor foi medida em linhas de código por dia. Levou tempo para reconhecermos que esse indicador incentivava exatamente os comportamentos errados, código verboso, redundante e sem valor real. A história está se repetindo com outro medidor.
A produtividade real em software não é sobre quanto código você escreve. É sobre quanto problema você resolve com o mínimo de complexidade necessária.
2. O Que É Carga Cognitiva (e Por Que Deveria Te Preocupar)
Antes de avançar, preciso explicar o conceito central desse artigo. Se você é desenvolvedor (ou qualquer outro cargo) e nunca ouviu falar em Carga Cognitiva, este é provavelmente o conceito mais importante que você vai aprender hoje.
A Teoria da Carga Cognitiva
Em 1988, o psicólogo educacional John Sweller publicou um paper que mudaria a forma como entendemos aprendizado e performance. Ele definiu três tipos de carga cognitiva:
| Tipo | O que é | Exemplo no dev |
|---|---|---|
| Intrínseca | Complexidade inerente da tarefa | Entender um algoritmo de consenso distribuído |
| Estranha (extraneous) | Overhead desnecessário do ambiente/ferramentas | Navegar documentação confusa, configs quebradas |
| Germane | Esforço para construir esquemas mentais duradouros | Aprender padrões de design pela primeira vez |
A carga intrínseca é inevitável, é a natureza do problema. A carga estranha é desperdício e deveria ser eliminada. E a carga germane é investimento: é o que faz você crescer como profissional.
O ponto crucial: a capacidade cognitiva de um ser humano é limitada. Quando a carga estranha aumenta, sobra menos espaço para a intrínseca e a germane.
Carga Cognitiva no Framework DevEx
Em 2023, Abi Noda, Nicole Forsgren, Margaret-Anne Storey e Michaela Greiler publicaram na ACM Queue o paper “DevEx: What Actually Drives Productivity”. Nele, identificaram três dimensões centrais da experiência do desenvolvedor:
- Feedback Loops: a velocidade e qualidade das respostas às ações do dev
- Cognitive Load: a quantidade de processamento mental necessária para realizar uma tarefa
- Flow State: o estado de imersão total e foco energizado
Essas três dimensões são interdependentes. Quando a carga cognitiva é alta, o flow state é prejudicado. Quando os feedback loops são lentos, a carga cognitiva aumenta.
O paper é enfático:
“Cognitive load impedes developers’ most important responsibility: delivering value to customers.”
“A carga cognitiva impede a responsabilidade mais importante dos desenvolvedores: entregar valor para os clientes.”
Team Topologies e Carga Cognitiva em Times
Matthew Skelton e Manuel Pais, no livro Team Topologies, trouxeram o conceito de carga cognitiva para o nível organizacional. Eles argumentam que a carga cognitiva de um time deve ser um fator determinante na definição dos limites de responsabilidade. Se um time é responsável por mais do que consegue manter na cabeça coletivamente, a qualidade cai e o burnout sobe.
Agora, a pergunta que me incomoda:
A IA está reduzindo a carga estranha ou apenas substituindo por uma nova forma de carga estranha?
Minha experiência diz que é a segunda. E as evidências apontam na mesma direção.
3. Como a IA Está Aumentando a Carga Cognitiva
Aqui é onde as coisas ficam concretas. Vou usar uma combinação de pesquisas da Thoughtworks (publicadas no site do Martin Fowler), frameworks acadêmicos e minha experiência pessoal.
3.1 — A Revisão Que Nunca Acaba
O papel do desenvolvedor está mudando. Antes, éramos primariamente escritores de código. Com IA, estamos nos tornando primariamente revisores de código.
Birgitta Böckeler, Distinguished Engineer na Thoughtworks com mais de 20 anos de experiência, relatou sua experiência com agentes de codificação (Cursor, Windsurf, Cline):
“Always carefully review AI-generated code. It’s very rare that I do NOT find something to fix or improve.”
“Revise sempre o código gerado por IA. É muito raro que eu NÃO encontre algo para corrigir ou melhorar.”
Isso é profundamente significativo. Não estamos falando de uma sugestão aqui e ali. Estamos falando de sessões inteiras onde o agente gera centenas de linhas de código que precisamos (não tem choro, aqui precisamos realmente revisar e garantir, ou estamos arriscando a qualidade) ler, entender e avaliar. Código que não nasceu da nossa cabeça.
Minha experiência: Eu uso Copilot e agentes diariamente. Em um dia típico, eu reviso 3-4x mais código do que escrevo diretamente. E a revisão de código que você não escreveu é cognitivamente muito mais pesada do que a revisão do seu próprio código. Você não tem o contexto de por que cada decisão foi tomada. Cada linha é um mini-enigma.
Kief Morris, da Thoughtworks, capturou essa tensão perfeitamente ao descrever os humanos como potenciais gargalos no processo:
“Agents can generate code faster than humans can manually inspect it.”
“Agentes conseguem gerar código mais rápido do que humanos conseguem inspecioná-lo manualmente.”
O resultado? Mais código para revisar do que nunca, com menos contexto do que nunca.
3.2 — Rabbit Holes e Diagnósticos Errados
A IA erra. Frequentemente. E quando erra, o dev precisa gastar energia mental significativa para perceber o erro, entender por que aconteceu e redirecionar.
Böckeler documentou exemplos concretos:
- Diagnóstico errado de Docker: A IA assumiu que um problema de build era causado por configurações de arquitetura, quando na verdade era por copiar
node_modulescompilados para a arquitetura errada. Um dev experiente reconheceu o problema imediatamente. - Brute-force em vez de root cause: Ao encontrar um erro de memória durante um Docker build, a IA aumentou as configurações de memória em vez de investigar por que tanta memória estava sendo usada.
- Soluções excessivamente complexas: A IA gerou um web component elaborado para exibir dados de um JSON, muito além do que era necessário naquele momento.
- CSS redundante: A cada mudança de CSS feita pela IA, Böckeler precisava remover “às vezes quantidades massivas de estilos CSS redundantes, um por um.”
Minha experiência: Já perdi horas em sessões onde a IA foi por um rabbit hole, eu não percebi a tempo, e o resultado foi uma mudança enorme que precisou ser descartada. Aquela sensação de ter trabalhado o dia inteiro e no final ter que fazer git reset --hard? É devastadora. E é um tipo de exaustão que não existia antes.
3.3 — O Custo Oculto do Contexto
Existe um custo cognitivo que quase ninguém menciona: manter na cabeça o que a IA fez, por que fez, e se está correto.
Kief Morris, no artigo “Humans and Agents in Software Engineering Loops”, descreve três posições para humanos em relação à IA:
- Humanos fora do loop (vibe coding): a IA faz tudo, você só diz o que quer. Funciona para protótipos, perigoso para produção.
- Humanos no loop: você inspeciona cada linha gerada. Seguro, mas você se torna um gargalo.
- Humanos no loop (on the loop): você não corrige o output, você melhora o processo que gera o output (harness engineering).
O problema com “humanos no loop” é que gera uma carga cognitiva enorme. Você precisa manter dois modelos mentais simultaneamente: o que você faria e o que a IA fez, e comparar os dois continuamente.
Böckeler descreveu isso como “constant risk assessment”:
“Hallucinations are the core feature of LLMs. We just call it ‘hallucinations’ when they do something we don’t want, and ‘intelligence’ in the cases where it’s useful to us.”
“Alucinações são a funcionalidade central dos LLMs. A gente só chama de ‘alucinação’ quando eles fazem algo que não queremos, e de ‘inteligência’ nos casos em que é útil.”
A não-determinismo dos LLMs significa que toda interação é uma avaliação de risco. Cada sugestão aceita é uma decisão tomada. E decisões cansam.
3.4 — Interrupção do Flow State
Lembram das três dimensões do DevEx? Feedback Loops, Cognitive Load e Flow State. As três estão interconectadas.
Cada sugestão da IA é uma micro-interrupção. Não no sentido de “alguém te chamou no Slack”, mas no sentido de “você precisa tomar uma micro-decisão”: aceitar, rejeitar ou editar. À primeira vista, parece insignificante. Mas estudos sobre interrupções mostram que mesmo micro-decisões frequentes degradam o flow state ao longo do tempo.
Minha experiência: Percebi que nas sessões mais longas com agentes, mesmo quando estou “produzindo” muito, eu termino mais exausto do que nos dias em que codifico manualmente. A produção sobe, mas o custo cognitivo sobe mais. É como correr numa esteira: você está se movendo, mas não necessariamente avançando.
Böckeler recomenda:
“Stop AI coding sessions when you feel overwhelmed by what’s going on. Either revise your prompt and start a new session, or fall back to manual implementation — ‘artisanal coding’, as my colleague Steve Upton calls it.”
“Pare as sessões de codificação com IA quando sentir que está sobrecarregado com o que está acontecendo. Revise seu prompt e comece uma nova sessão, ou volte para a implementação manual, o ‘artisanal coding’, como meu colega Steve Upton chama.”
Eu gosto desse termo: artisanal coding. A ideia de que, em certos momentos, codar manualmente não é um retrocesso, é um ato intencional de preservação da sanidade cognitiva.
4. Polêmicas Que a Indústria Prefere Ignorar
Aqui eu vou ser mais direto. Existem conversas que a indústria, especialmente quem vende ferramentas de IA, prefere não ter. Vamos ter.
4.1 — “Desenvolvedores Vão Ser Substituídos por IA”
A manchete que não morre. E a resposta curta: não no horizonte visível.
Böckeler, após meses de uso intensivo de agentes de codificação, foi categórica:
“By no stretch of my personal imagination will we have AI that writes 90% of our code autonomously in a year.”
“Por mais que eu tente imaginar, não vejo como teremos IA escrevendo 90% do nosso código de forma autônoma em um ano.”
O que está acontecendo é uma transformação do papel. De escritor de código para orquestrador de agentes, revisor de outputs e engenheiro de contexto. É um papel diferente, não necessariamente menor, mas diferente. E que, paradoxalmente, exige mais experiência e julgamento, não menos.
Böckeler classificou os erros da IA em três raios de impacto:
- Tempo até o commit: A IA te atrasa em vez de acelerar. Frustrante, mas localizado
- Fluxo do time na iteração: Mudanças que criam fricção para outros devs: doctor workflows ruins, requisitos mal interpretados
- Manutenibilidade de longo prazo: O raio mais insidioso: código que funciona agora mas será difícil de mudar depois
O mais preocupante: o raio de impacto 3 é onde a experiência de 20+ anos de Böckeler mais fez diferença. Exatamente o tipo de julgamento que um humano traz e que a IA não tem.
4.2 — Vibe Coding vs. Engenharia de Software
“Vibe coding” virou moda. A ideia: você descreve o que quer, a IA faz, você aceita. Kief Morris descreveu isso como “humanos fora do loop”, e fez uma provocação fundamental:
“If the LLMs can write and change code without us, do we care whether the code is ‘clean’?”
“Se os LLMs conseguem escrever e alterar código sem nós, importa se o código é ‘limpo’?”
A resposta dele (e a minha): sim, importa. Não por estética, mas por razões pragmáticas. Código limpo e bem estruturado não é um capricho, é o que permite que o software evolua sem colapsar sob seu próprio peso. E isso vale tanto para humanos quanto para LLMs:
“When LLMs can more quickly understand and modify the code they work faster and spiral less.”
“Quando os LLMs conseguem entender e modificar o código mais rapidamente, eles trabalham mais rápido e divagam menos.”
Böckeler trouxe o teste definitivo:
“Se você estivesse de plantão para a aplicação que está desenvolvendo, em que ponto você estaria ok em deploiar uma mudança de 1.000 ou 5.000 LOC?”
Se essa pergunta te dá arrepios, você entende por que vibe coding como estratégia de produção é uma roleta russa.
4.3 — Produtividade Real vs. Percebida
Este é talvez o ponto mais sutil e perigoso. Os estudos do GitHub/Accenture mostram que desenvolvedores se sentem mais produtivos com IA. Mas sentir-se produtivo e ser produtivo são coisas diferentes.
Pull requests por desenvolvedor ≠ valor entregue.
“55% mais rápido”… mais rápido em quê? Na digitação? No entendimento do problema? Na entrega de valor para o usuário?
As métricas que a indústria usa para medir o impacto da IA são, em sua maioria, métricas de output (volume de código, velocidade de geração, PRs abertos) e não métricas de outcome (bugs em produção, tempo de resolução de incidentes, satisfação do usuário).
O DORA (DevOps Research and Assessment), do Google, vem trabalhando nisso com o AI Capabilities Model (2025), tentando criar um framework mais holístico. Mas ainda estamos longe de ter métricas que capturem o custo cognitivo real das ferramentas de IA.
4.4 — Juniors Sendo Prejudicados
Esta é a polêmica que mais me preocupa pessoalmente.
Lembram dos três tipos de carga cognitiva? A germane é o esforço para construir esquemas mentais duradouros. É o que faz o junior que hoje luta com um loop for virar o sênior que rapidamente entende um problema de concorrência.
Quando a IA faz o boilerplate, resolve o algoritmo, gera o teste e sugere o refactoring, quando o junior aprende os fundamentos?
O DORA abordou isso em “Managing AI dependency: How students are establishing guardrails with AI” e “AI as a tutor”. A ideia de IA como tutor é interessante, mas exige intencionalidade. Sem essa intencionalidade, o que acontece é o oposto: a IA se torna uma muleta que impede o desenvolvimento de habilidades fundamentais.
Böckeler tocou nisso indiretamente:
“I imagine that even with AI, new developers will learn this by falling into these pitfalls and learning from them, the same way I did. The question is if the increased coding throughput with AI exacerbates this to a point where a team cannot absorb this sustainably.”
“Imagino que, mesmo com IA, novos desenvolvedores vão aprender caindo nessas armadilhas e aprendendo com elas, da mesma forma que eu aprendi. A questão é se o aumento de throughput de código com IA agrava isso a um ponto onde um time não consegue absorver de forma sustentável.”
Traduzindo: se a IA gera código mais rápido do que o junior consegue absorver e aprender, o time simplesmente não consegue sustentar a qualidade. É um ciclo vicioso.
4.5 — Qualidade de Código e Code Churn
A pesquisa da GitClear é devastadora nesse ponto. Analisando 153 milhões de linhas de código:
- Code churn dobrando (linhas revertidas/alteradas em menos de 2 semanas)
- Mais código adicionado e copiado, menos código movido, refatorado ou deletado
- Padrões que lembram contribuidores temporários, não membros do time
Böckeler documentou problemas específicos de qualidade:
- Testes verbosos e redundantes: A IA cria funções de teste novas em vez de adicionar assertions às existentes. Mais testes ≠ melhor teste suite. Testes duplicados tornam a suite frágil e cara de manter.
- Falta de reuso: A IA não percebe que um componente já existe no codebase, e cria duplicatas.
- Código excessivamente complexo: Mais linhas, mais funcionalidade do que o necessário, introdução de parâmetros desnecessários no lugar de usar a cadeia de injeção de dependência existente.
Tudo isso é dívida técnica sendo criada mais rápido do que nunca. E dívida técnica é… carga cognitiva futura.
4.6 — Segurança
Precisamos falar de segurança. LLMs são treinados em código aberto, incluindo código vulnerável. Quando a IA sugere uma query SQL, ela pode estar sugerindo uma SQL injection. Quando gera autenticação, pode estar pulando validações críticas.
Jim Gumbley e Lilly Ryan, da Thoughtworks, publicaram “Coding Assistants Threaten the Software Supply Chain” (2025), argumentando que assistentes de código ampliam a superfície de ataque da cadeia de suprimentos de software. O problema não é só o código que a IA gera, é o código que ela sugere que você aceite sem revisar.
Lembrem: o OWASP Top 10 não muda porque a IA está gerando código. Injection, broken authentication, security misconfiguration, todos continuam lá. Mas agora, com a velocidade de geração de código pela IA, as vulnerabilidades também são produzidas mais rápido.
E se o dev está cognitivamente sobrecarregado (por tudo que discutimos nas seções anteriores), qual a probabilidade de ele pegar uma vulnerabilidade sutil em um bloco de 200 linhas gerado automaticamente?
5. O Que Fazer Com Tudo Isso
Não quero que este artigo pareça um manifesto anti-IA. Não é, mesmo eu tendo passado por um período de ceticismo forte em 2024/2025 sobre IA. Eu uso IA todos os dias e ela genuinamente me ajuda em muitas situações. Mas precisamos de uma conversa mais honesta sobre os custos.
Aqui estão recomendações práticas, baseadas nas pesquisas citadas e na minha experiência:
Para Desenvolvedores
- Sempre revise código gerado por IA. Sem exceções. Böckeler: é muito raro NÃO encontrar algo para corrigir.
- Pare quando sentir overwhelm. Não tem vergonha em voltar para o “artisanal coding”. É um ato de inteligência, não de fraqueza.
- Desconfie de soluções mágicas. Se a IA resolveu um problema complexo em 30 segundos, provavelmente tem algo errado: ou simplificado demais, ou incorreto de formas sutis.
- Pratique pair programming. Quatro olhos pegam mais que dois, e dois cérebros são menos complacentes. Isso vale especialmente quando um dos “programadores” é uma IA.
- Monitore sua exaustão. Se no final do dia você produziu muito mas está destruído, considere que o custo cognitivo está alto demais.
Para Times e Liderança
- Não pressione para “entregar mais porque agora tem IA”. Böckeler: “An organization that puts high pressure on their teams to deliver faster ‘because you now have AI’ is more exposed to the quality risks.”
- Invista em code quality monitoring. SonarQube, Codescene, ou qualquer ferramenta que te alerte sobre code smells. Alguns smells se tornam mais proeminentes com IA (especialmente duplicação de código) e devem ser monitorados mais de perto.
- Crie um log de “Go-wrong”. Registre eventos onde código gerado por IA causou fricção no time ou afetou manutenibilidade. Reflita sobre eles semanalmente.
- Use custom rules/instructions. A maioria dos assistentes suporta regras customizadas. Use-as para codificar boas práticas do time. Mas aceite que a IA não vai segui-las 100% das vezes.
- Cultive confiança e comunicação aberta. Estamos todos aprendendo. Times com alta confiança e segurança psicológica aprendem mais rápido e lidam melhor com os desafios da adoção de IA.
Para a Formação de Juniors
- Garanta que passem pelos fundamentos. Algoritmos, estruturas de dados, padrões de design, debugging manual. Tudo isso constrói a carga germane que vai fazer a diferença na carreira.
- Use IA como tutor, não como muleta. Peça para a IA explicar, não para resolver. Peça para revisar o código do junior, não para escrever o código por ele.
- Crie momentos de “sem IA”. Code reviews, dojos, exercícios de fundamentos. Espaços intencionais onde o junior desenvolve músculos que a IA não pode desenvolver por ele.
6. Reflexão Final
Eu comecei este artigo com uma afirmação provocativa: nunca produzimos tanto código, mas nunca fomos tão exaustos. Ao longo do texto, tentei fundamentar isso com dados, pesquisas e experiência.
A IA é uma ferramenta poderosa. Toda ferramenta poderosa tem tradeoffs. A serra elétrica é mais rápida que a serra manual, mas exige mais atenção, mais respeito e mais equipamento de proteção. A IA no desenvolvimento é a mesma coisa.
O custo real não é financeiro, é cognitivo. Estamos gastando a capacidade mental dos desenvolvedores em revisar código que não escreveram, redirecionar agentes que tomaram o caminho errado, avaliar sugestões a cada segundo, e manter modelos mentais duplos de “o que a IA fez” vs “o que eu faria”.
Estamos produzindo mais código. Mas estamos produzindo melhor software?
Não tenho uma resposta definitiva. E desconfio de quem tem. Mas sei que a conversa precisa ser mais honesta. As empresas de ferramentas de IA têm incentivos para apresentar só o lado bom. Os números de adoção e satisfação são reais, mas são incompletos. Precisamos de métricas que capturem o custo total, incluindo o cognitivo.
Enquanto isso, cuide da sua cabeça. Monitore sua exaustão. Não aceite que “mais output” significa automaticamente “mais valor”. E não tenha medo de, às vezes, fechar o Copilot e escrever código com as próprias mãos.
Às vezes, artisanal coding é exatamente o que você precisa.
E você aí? Como tem sido essa tensão entre produtividade e custo cognitivo no dia a dia? Já percebeu que termina os dias mais exausto mesmo tendo “produzido mais”? Tem alguma técnica que funcionou para você? Comenta aqui no post. Quero muito saber o que vocês estão sentindo na prática, porque essa é uma conversa que a indústria ainda precisa aprender a ter e eu particularmente estou curioso de como ela deveria ser conduzida.
Referências
- Gao, Y. et al. (GitHub/Accenture, 2024) — “Research: Quantifying GitHub Copilot’s impact in the enterprise with Accenture” — github.blog
- GitClear (2024) — “Coding on Copilot: 2023 Data Suggests Downward Pressure on Code Quality” — gitclear.com
- Böckeler, B. (Thoughtworks, 2025) — “The role of developer skills in agentic coding” — martinfowler.com
- Böckeler, B. (Thoughtworks, 2025) — “I still care about the code” — martinfowler.com
- Morris, K. (Thoughtworks, 2026) — “Humans and Agents in Software Engineering Loops” — martinfowler.com
- Noda, A.; Forsgren, N.; Storey, M.; Greiler, M. (ACM Queue, 2023) — “DevEx: What Actually Drives Productivity” — queue.acm.org
- DORA/Google (2025) — “AI Capabilities Model” e “State of AI-assisted Software Development” — dora.dev
- Sweller, J. (1988) — “Cognitive load during problem solving: effects on learning” — Cognitive Science, 12(2), 257–285
- Skelton, M.; Pais, M. (2019) — “Team Topologies: Organizing Business and Technology Teams for Fast Flow” — IT Revolution Press
- Gumbley, J.; Ryan, L. (Thoughtworks, 2025) — “Coding Assistants Threaten the Software Supply Chain” — martinfowler.com
- Böckeler, B. et al. (Thoughtworks, 2023–2026) — “Exploring Generative AI” (série completa) — martinfowler.com
- Forsgren, N.; Storey, M.; et al. (2021) — “The SPACE of Developer Productivity” — Communications of the ACM